Livre blanc : 10 Problèmes
10 problèmes de réseau courants que PRTG Network Monitor vous aide à résoudre
Introduction
La journée routinière d'un administrateur système est rythmée par les questions courantes que leur posent les collègues, les superviseurs et les clients. Nous devons traiter des questions similaires de manière relativement fréquente:
- Pourquoi est-ce que mes applications sont si lentes et que s'est-il passé avec mes calculs la nuit dernière ? Envisagez-vous d'améliorer nos ressources matérielles prochainement afin de remédier à ces défaillances ?
- Veuillez me fournir un rapport sur la durée active du système de toute la semaine dernière. Ma réunion commence dans environ une heure et j'en ai besoin maintenant !
- Pourquoi est-ce que mon Outlook ne reçoit aucun e-mail ?
- Pourquoi est-ce que je reçois des alertes sur les temps d'arrêt des appareils alors que les appareils de mes collègues sont déjà en cours de maintenance ?
- Pourquoi est-ce que l'exécution de notre base de données est si médiocre le matin ?
- Pourquoi est-ce que je dois toujours vous appeler en premier lorsque le toner de notre imprimante est vide ?
- Pourquoi est-ce que ma machine virtuelle se bloque si souvent ?
- Êtes-vous sûr que notre réseau est vraiment sécurisé et qu'aucune personne non autorisée ne peut y accéder?
- Pourquoi est-ce que la qualité audio des appels téléphoniques est se mauvaise et pouvez-vous régler le problème des flux vidéos qui sont en permanence en retard ?
- Savez-vous que notre page web est incroyablement lente et que les clients abandonnent fréquemment les processus d'achat ?
Vous devez traiter ces questions rapidement et de manière exhaustive. Pour ce faire, vous avez besoin d'un support.
Vous devez déjà connaître de nombreuses listes dans PRTG permettant de faciliter vos fonctions d'administrateur système : appareils préférés, meilleur temps de disponibilité, ping le plus rapide, usage bande passante le plus élevé, site web le plus lent, espace disque libre, capteurs avec statut panne ou par leurs balises, etc. Ces listes vous permettent d'effectuer des recherches sur l'ensemble de votre réseau et de le contrôler intégralement. Nous vous proposons ci-après d'autres listes utiles: Cet article présente dix problèmes de réseau courants tels qu'ils vous sont adressés et la manière avec laquelle PRTG vous permet de les résoudre rapidement.
Coup d'œil sur votre réseau et ses besoins
Reconnaissance précoce des problèmes matériels potentiels et planification de l'amélioration des ressources matérielles
Votre infrastructure IT nécessite un bilan constant. Votre mission consiste à garantir le bon fonctionnement de votre système. Est-ce que des composants sont surchargés, par exemple, l'UC ou la mémoire ? Est-ce que la température de vos serveurs est correcte ?
Est-ce que des serveurs Windows redémarrent intempestivement la nuit sans que vous ne soyez au courant de ce problème, passant ainsi à côté d'un événement anormal? Vous voulez également savoir quand les disques durs de votre environnement seront pleins, quand la mémoire sera manquante ou quand il sera nécessaire de mettre à jour votre connexion internet en raison d'un usage accru de la bande passante. Si vous détenez ces informations, vous saurez également quand il convient d'investir dans de nouvelles ressources matérielles.
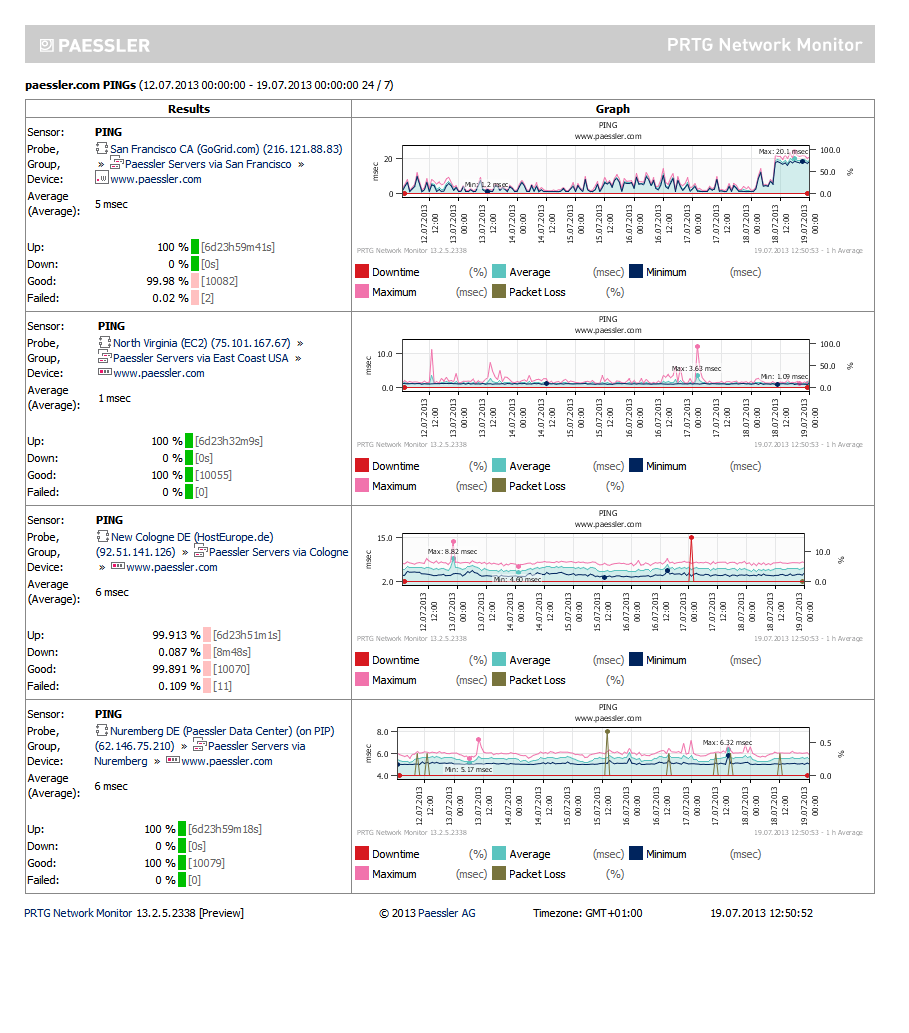
PRTG vous fournit des données d'analyse détaillées et des rapports historiques sur l'ensemble de vos composants réseau. L'analyse vous permet de connaître les tendances d'utilisation afin de savoir quand les ressources manqueront. PRTG vous avertira quand quelque chose d'anormal se produit, par exemple des pannes du serveur ou lorsque certaines valeurs atteignent un seuil défini, et vous le notifiera immédiatement. Vous pourrez ainsi réagir avant que la situation n'empire.
ILLUSTRATION: Rapport lié aux capteurs ping
Surveillance sans panne sans intervalles
dans les données
Vous surveillez les niveaux de service ? Vous souhaitez créer des données de facturation fiables ? Vous dépendez d'une surveillance ne tolérant aucune panne ? Votre outil de surveillance doit alors afficher un taux de fonctionnement de 100 % ! La durée active du système peut être réduite en raison de connexions défaillantes. Différents motifs peuvent expliquer des pannes Internet à l'emplacement d'un serveur PRTG, la défaillance du matériel ou un temps mort en raison d'une mise à jour logicielle du système d'exploitation ou de PRTG lui-même, ou les intervalles dans la surveillance des données.
Afin de garantir une surveillance sans défaillance, PRTG fournit un clustering par basculement. Cette fonctionnalité est incluse dans chaque licence sans coût supplémentaire. Il existe un « Nœud principal » et un ou plusieurs « Nœuds de basculement », chaque nœud étant une installation PRTG complète, dans un LAN ou à plusieurs emplacements dans le monde. Chaque nœud peut assurer lui-même la surveillance complète et donner l'alerte, Les nœuds sont connectés entre eux et peuvent communiquer dans les deux directions. Dans une configuration de basculement simple, un nœud peut assurer le rôle d'un autre nœud si ce dernier subit une panne. Vous évitez ainsi les temps morts de la surveillance et vous garantissez une surveillance sans interruption et une alerte indépendante depuis un site unique, un centre de données ou une connexion réseau.
Échec des services Windows et blocages du serveur
En cas d'erreur serveur, une des méthodes de récupération les plus courantes consiste à redémarrer le serveur pour remettre en ligne le service en échec. Pendant la surveillance des services Windows, vous recevrez une notification pas SMS, courrier électronique, etc., en cas d'interruption de service. Dans certains cas, le redémarrage automatique peut s'avérer encore plus utile. Il en est de même pour les blocages occasionnels du système. Dans ce cas, les services Windows sont interrompus. PRTG le reconnaît et envoie une notification mais le démarrage doit s'effectuer manuellement.
Le système de notification de PRTG permet d'effectuer aisément un redémarrage automatique. De manière spécifique, le système de notifications de PRTG remplit d'autres fonctions que la simple notification. Il suffit de créer un script qui redémarre les services ou le système global et de recourir à une notification « Exécuter Programme ». Si un service ou un serveur est en panne pendant un intervalle de temps défini, PRTG exécute ce script et le redémarrage s'effectue sans votre intervention. La surveillance de services Windows spécifiques via le capteur de service WMI de PRTG permet même de choisir une option de redémarrage automatique si un service est en panne!
Temps d'arrêt planifiés: Les alertes sont inutiles et gênantes
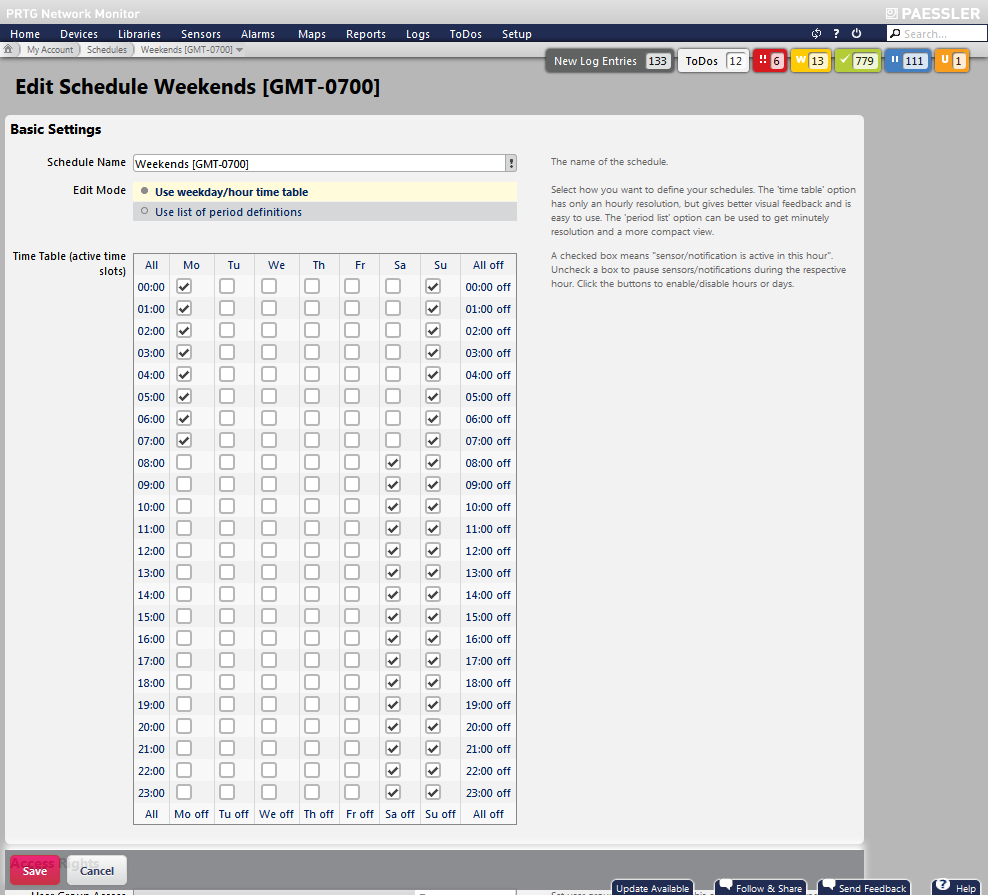
Il est parfois nécessaire de mettre les appareils hors service, par exemple, pour des raisons de maintenance. Vous pouvez également arrêter les systèmes le week-end ou la nuit ou vous souhaitez simplement ne pas recevoir de notifications à certains moments. Vous ne souhaitez pas recevoir des alertes de PRTG en raison de ces temps d'arrêt planifiés ; PRTG remplit cette fonction dans le but de garantir une disponibilité optimale du système en vous notifiant. Mettre en pause manuellement la surveillance de certains capteurs de votre important réseau est évidemment une tâche fastidieuse.
Nos développeurs ont ainsi implémenté une fonction dédiée à la maintenance et à d'autres temps d'arrêt planifiés. Pour chaque groupe, appareil ou tout autre objet, vous pouvez définir des calendriers visant à limiter automatiquement le temps de surveillance. Cela permet ainsi d'éviter les fausses alarmes et de ne pas être notifié en cas de temps d'arrêt.
ILLUSTRATION: Calendriers variables
Garantir le fonctionnement des systèmes de base
Exécution médiocre de la base de données
Si l'exécution de la base de données est médiocre, vous devez savoir quelle partie doit être analysée pour optimiser les performances de la base de données. Malheureusement, l'examen du motif expliquant la mauvaise exécution des serveurs SQL par exemple peut être une tâche fastidieuse.
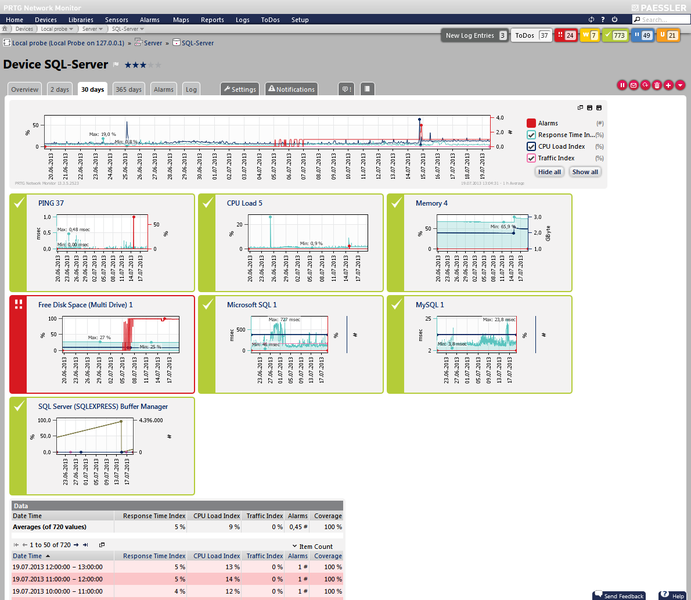
PRTG vous aide à assurer la maintenance de votre base de données. En effet, les capteurs du Serveur SQL Microsoft WMI indiquent le nombre de connexions utilisateurs. Les performances médiocres de la base de données à certains moments peuvent s'expliquer par le nombre excessif de connexions utilisateurs simultanées. Ce capteur peut également afficher le pourcentage de pages trouvées dans le cache des tampons sans avoir à procéder à une lecture depuis le disque. Si ce nombre est trop faible et si PRTG vous adresse immédiatement une notification, vous pouvez augmenter la quantité de mémoire disponible du serveur SQL. Vous adressez des requêtes inefficaces? PRTG mesure le temps de réponse des requêtes et peut vérifier si la valeur de la réponse est la valeur attendue.
ILLUSTRATION: Données de surveillance pour
un serveur SQL
Maintenance d'imprimante chronophage
En tant qu'administrateur système, vous ne souhaitez pas gaspiller votre temps précieux à vérifier manuellement et tous les jours le statut des imprimantes de votre infrastructure IT. Il est parfois également gênant d'être appelé à l'étage supérieur en raison d'une insuffisance de papier alors que vous êtes concentré sur une tâche, tentant de solutionner des problèmes de serveur SQL que PRTG vous a récemment notifiés.
PRTG vous fournit la solution : par exemple, l'utilisation du capteur File d'attente à l'impression de Windows pour surveiller toutes les tâches sur un serveur d'impression. En cas d'insuffisance de papier, PRTG vous adresse un message vous permettant de réagir avant que les collègues vous le demandent. Vous pouvez alternativement surveiller les paramètres matériels de vos imprimantes LaserJet HP à l'aide d'un capteur disponible en mode natif. Obtenez une notification lorsque le toner est faible.
Ou, encore mieux, PRTG envoie automatiquement un courrier électronique à votre fournisseur pour procéder à la livraison de toners neufs et à l'échange des anciens. Vous n'avez ainsi plus à vous soucier du statut des imprimantes.
Environnements virtuels avec comportement non fiable
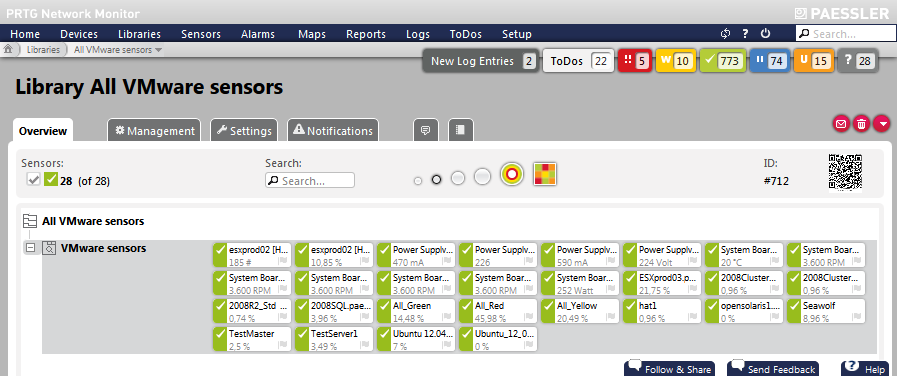
Il est important de surveiller en permanence les machines virtuelles dans un contexte d'infrastructures IT hautement flexibles où la virtualisation jour un rôle majeur. Plusieurs raisons peuvent être à l'origine des problèmes survenant avec les machines virtuelles. PRTG fournit différents capteurs permettant de solutionner ces problèmes. Ajoutez un capteur Machine virtuelle VMware à PRTG pour surveiller l'UC et l'utilisation de la mémoire de vos machines virtuelles via SOAP, ainsi que la vitesse du réseau d'une seule machine virtuelle. Que se passe-t-il toutefois si la vitesse est trop lente ou si la mémoire est surchargée sur une MV?
Il est utile de pouvoir également surveiller le matériel hôte à l'aide de PRTG. Vous pouvez immédiatement comprendre si l'origine des problèmes survenant sur vos machines virtuelles est une panne du matériel hôte. Si le statut général de votre VMware hôte est autre que « normal », alors le problème sera signalé dans le message du capteur. En raison de la fonction de dépendance de PRTG, peu de temps vous sera nécessaire pour déterminer si le problème est dû à une seule MV ou au matériel.
ILLUSTRATION: Capteurs pour VMware
Garantir la qualité et la sécurité de votre réseau
Détection des problèmes de sécurité de votre réseau
Comment est-il possible de garantir la sécurité de votre réseau ? D'une part, il est important de garantir le fonctionnement et la mise à jour des scanneurs antivirus de tous les ordinateurs. En outre, la dernière version de Windows doit être exécutée afin de ne pas omettre les différentes mises à jour de sécurité. D'un autre côté, vous pouvez déjà subir une attaque en dépit de ces protections. Des affluences fortes et inhabituelles de l'UC peuvent indiquer une attaque potentielle.
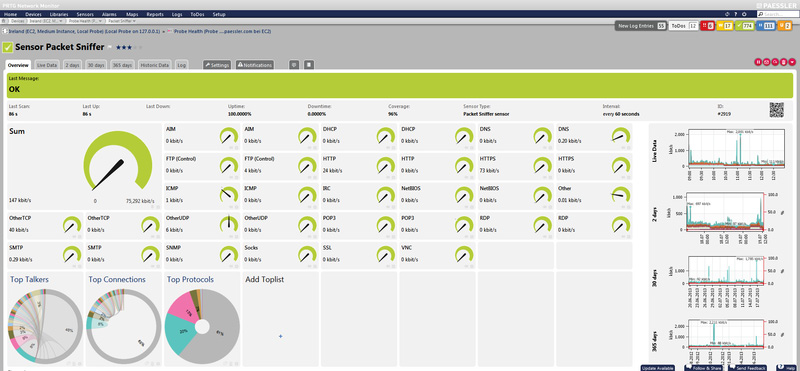
PRTG détecte tout comportement inhabituel et bascule les capteurs correspondant en mode « inhabituel ». Vous pouvez également vérifier les connexions de votre réseau: Est-ce que des connexions sont réalisées via votre pare-feu depuis des adresses sources
inconnues? La fonction Liste des principaux éléments des différents capteurs de trafic permet d'analyser ce type de connexion pour garantir la sécurité. L'analyse d'un capteur similaire est une autre fonction utile de surveillance de la sécurité permettant de reconnaître des interconnexions inhabituelles entre les capteurs. PRTG surveille également le statut de sécurité global tel que le logiciel antivirus d'un ordinateur Windows à l'aide du capteur Centre de sécurité WMI et les mises à jour du serveur Windows à l'aide du capteur Statistiques WSUS.
ILLUSTRATION: Analyse des connexions
via Packet Sniffer
Qualité du service: Mauvaise qualité audio de VoIP et
dysfonctionnement du flux vidéo
Si la qualité audio des appels de Voix sur IP (VoIP) chute considérablement ou si le flux vidéo présente de fréquentes anomalies, vous devez analyser les différents paramètres tels que l'instabilité, la perte de paquets ou la variation du retard de paquet de la connexion réseau. Quelle peut être l'origine du problème ? Les services VoIP et le flux vidéo dépendent largement du flux constant des paquets de données. Par exemple, la qualité du service chute lorsque les paquets UDP ne sont pas reçus à temps ou si les paquets sont perdus ou hors service.
PRTG est l'outil parfait pour détecter ces problèmes. Le capteur opérationnel Qualité de service (QoS) permet de mesurer la qualité de votre connexion réseau en envoyant des paquets UDP entre deux sondes distantes et en analysant les différents paramètres réseau. Vous pouvez également surveiller les paramètres VoIP concernés sur la base des résultats de l'Accord sur le niveau de service IP provenant des appareils Cisco. Il suffit d'ajouter le Capteur SLA IP Cisco de PRTG et de s'assurer que les performances réseau sont adaptées pour VoIP.
Garantir la disponibilité et éviter les mauvaises
performances des pages web
La disponibilité et les temps de chargement des pages web sont un point crucial pour les entreprises, non pas uniquement pour les magasins en ligne qui doivent être accessibles jour et nuit tout en présentant des performances acceptables. Pour les magasins en ligne, il est en outre très important que les requêtes fonctionnent comme prévu. Si un processus d'achat échoue en raison d'erreurs techniques ou si parcourir les éléments d'une page est horriblement lent et désagréable, vous perdrez des clients et de l'argent. Il en est de même si des clients potentiels parcourent le web pour obtenir des informations sur votre entreprise et que la page s'affiche trop lentement.
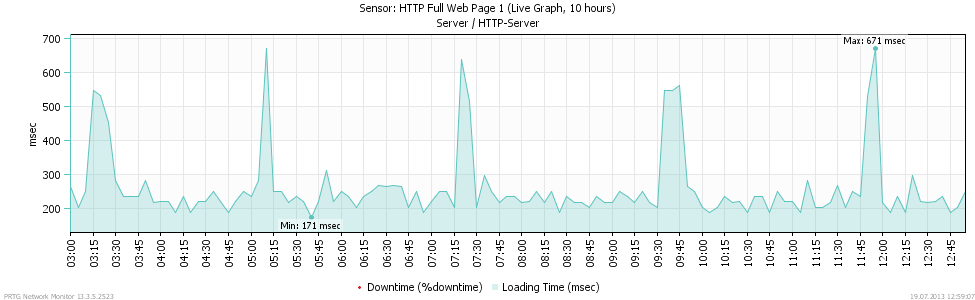
Afin d'éviter une perte potentielle de revenus pour votre entreprise, PRTG vous alerte immédiatement en cas de problème survenant sur votre page web ou si un comportement inhabituel est détecté, tel qu'une lenteur excessive. Utilisez le capteur Toute la page web HTTP, par exemple, qui affiche le temps de chargement de toute la page. Le capteur Transaction HTTP mesure les temps de chargement pour exécuter les transactions sur une page web interactive. Ajoutez de manière alternative le capteur ModStatus Apache
HTTP pour surveiller les accès et les données transférées pour identifier les pics de trafic à des périodes spécifiques, et savoir ainsi quand il est opportun de fournir plus de bande passante!
ILLUSTRATION: Graphique PRTG en temps
réel affichant le temps de
chargement d'une page Web
Conclusion
En tant qu'administrateur système, vous devez traiter de nombreuses requêtes provenant de votre réseau et des demandes de vos collègues. Le moniteur réseau PRTG peut vous aider à gérer de nombreux problèmes quotidiens. PRTG fournit également les fonctions vous permettant d'améliorer les performances de votre réseau, garantir le fonctionnement de vos systèmes de base ou la qualité et la sécurité de votre réseau.