Eine Datenbank ist eine durchsuchbare Sammlung von meist zusammenhängenden Informationen (Daten), die elektronisch gespeichert wird. Die Funktion einer Datenbank besteht nicht nur darin, Daten zu speichern, sondern auch darin, sie in einem Format zu speichern, das eine effiziente Suche und ein schnelles Abrufen von Informationen ermöglicht, sowie die Datensicherheit zu gewährleisten.
Datenbankfunktionen selbst sind Verfahren, die bestimmte Operationen mit Daten in einer Datenbank durchführen. Zu den Datenbankfunktionen gehören grundlegende CRUD-Operationen, wobei CRUD ein Akronym (create, read, update, delete data) für das Erstellen, Lesen, Aktualisieren und Löschen von Daten ist. In verschiedenen Computersprachen können diese grundlegenden Operationen andere Namen haben, z. B. insert anstelle von create.
Eine Datenbank wird von einem Datenbankmanagementsystem (DBMS) oder einem relationalen Datenbankmanagementsystem (RDBMS) verwaltet.
Datenbanksysteme sind eine Mischung aus physischer Hardware, die Daten speichert, komplexer DBMS- oder RDBMS-Software und verschiedenen Computersprachen für den Zugriff und die Bearbeitung von Daten.
Geschichte
Vor der ersten elektronischen Datenbank waren Aktenschränke, in denen Informationen wie Papierdokumente gespeichert und organisiert wurden und die effizient indiziert und durchsucht werden konnten, die nicht-elektronischen Datenbanken der damaligen Zeit.
Charles Bachman entwarf in den frühen 1960er-Jahren die erste computergestützte Datenbank, den Integrated Data Store (IDS). Mit dem IDS wurde das Konzept der Navigationsdatenbank eingeführt, das zwei Modelle umfasste: hierarchisch oder netzwerkartig, die beide nicht durchsuchbar waren. Durchsuchbare elektronische Datenbanken wurden in den 1970er-Jahren zusammen mit der strukturierten Abfragesprache (SQL) eingeführt, die eine Möglichkeit zur Durchführung von Datenbankabfragen bot. In den 2000er-Jahren wurde NoSQL entwickelt, um die Fülle an unstrukturierten Daten im Internet zu bewältigen. In den 2010er-Jahren wurde unter dem Einfluss der zunehmenden Mengen an Big Data und der Globalisierung des Internets der Dinge (IoT) ein verteiltes Datenbankmodell entwickelt, um die Speicherung von Daten an mehreren physischen Standorten zu ermöglichen.
Datenbankanwendungen
Überall dort, wo Daten gespeichert werden müssen, werden Datenbanken eingesetzt. Gängige Beispiele für den Einsatz von Datenbanken sind Bankensysteme, industrielle Anwendungen, staatliche Aufzeichnungen, Einzelhandel, elektronischer Handel, persönliche Finanzen und die meisten Arten von Online-Anwendungen. Zu den modernen Einsatzmöglichkeiten von Datenbanken gehören soziale Netzwerke, mobiles Computing, Cloud- und Datenanalyseanwendungen. Diese Arten von Anwendungen haben das Wachstum neuer Datenbanken und die Verwendung von gemischten Datenbanksystemen und Frameworks beeinflusst.
Datenbanken zeichnen sich durch die Art der gespeicherten Daten, die Methode für den Datenzugriff oder die Art der Datenspeicherung aus. Beispiele sind relationale, speicherinterne, hierarchische, virtualisierte, spaltenorientierte, Graphen-, Objekt-, verteilte, Streaming-, Zeitreihen- und Cloud-Datenbanken. Datenbanken können auch nach Funktion oder Branche kategorisiert werden, z. B. persönliche, kommerzielle, Endnutzer-, Blockchain-, Betriebs- und Netzwerkdatenbanken.
Strukturierte und unstrukturierte Daten
Die Art der Daten, die gespeichert und auf die zugegriffen werden muss, bestimmt, welche Art von Datenbank in einer Anwendung verwendet wird. Es gibt zwei Arten von Daten, die in Datenbanken gespeichert werden: strukturierte und unstrukturierte Daten. Strukturierte Daten haben eine bestimmte Länge und ein bestimmtes Format, zum Beispiel Zahlen, Daten und Zeichenketten. Sie werden in einer relationalen Datenbank gespeichert und mit einer Software namens SQL abgerufen. Zu den unstrukturierten Daten gehören Multimediadaten und Dokumentensammlungen. Sie werden in nicht-relationalen Datenbanken gespeichert und hauptsächlich über NoSQL abgerufen. Der Hauptunterschied zwischen relationalen und nicht-relationalen Datenbanken besteht darin, dass erstere explizit Beziehungen zwischen Datenobjekten definieren.
In relationalen Datenbanken sind die Daten in Zeilen und Spalten in separaten Tabellen organisiert. Die Datenstruktur ist von der physischen Struktur getrennt und die Daten können mithilfe eines Suchalgorithmus gefunden werden, der auf eindeutigen Beziehungskennungen basiert, die als Schlüssel bezeichnet werden. Relationale Datenbanken verwenden Schemata, d. h. Entwürfe, die beschreiben, wie die Daten organisiert sind. Relationale Datenbanken sind so konzipiert, dass sie eine Normalisierung ermöglichen, d. h., dass alle Daten nur an einer Stelle gespeichert werden. Eine relationale Datenbank ist das genaue Gegenteil einer hierarchischen Datenbank und verwendet ein Modell mit vielen Beziehungen zwischen mehreren Personen. Relationale Datenbanken sind zeilenorientiert, während nicht-relationale Datenbanken spaltenorientiert sind.
SQL-Abfragesprache
Eine relationale Datenbank wird auch als SQL-Datenbank bezeichnet, da sie die Computerabfragesprache SQL verwendet, um Daten zu finden, abzurufen, zu ändern und zu löschen.
Datenbanksprachen lassen sich in Datendefinitionssprachen (data definition languages) und Datenbearbeitungssprachen (data manipulation languages) einteilen. Zu den Datenbearbeitungssprachen gehören Datenabfragesprachen und prozedurale Sprachen. Zu den prozeduralen Sprachen gehört die Unterstützung von Kodierungsprozessen wie Iteration und Rekursion.
SQL ist eine Datendefinitionssprache, keine prozedurale Sprache. SQL ist häufig in eine allgemeine Hostsprache wie Cobol, C++, Python oder Java eingebettet, die Iterations- und Rekursionsfunktionen ausführen kann.
Beliebte Beispiele für relationale Datenbanken sind Microsoft SQL Server, MySQL, Oracle Database und IBM DB2.
Die Verwendung großer Mengen unstrukturierter Daten in modernen Anwendungen hat die Entwicklung nicht-relationaler Datenbanken ausgelöst. Nicht-relationale Datenbanken wurden entwickelt, um die Anforderungen an eine höhere Skalierbarkeit zu erfüllen. Nicht-relationale Datenbanken werden als NoSQL-Datenbanken bezeichnet, um sie von SQL- oder relationalen Datenbanken zu unterscheiden, und weil sie nicht die Abfragesprache SQL verwenden. NoSQL ist ein Akronym für „not SQL“, kann aber auch „not only SQL“ bedeuten.
NoSQL-Sprachen
Verschiedene Arten von NoSQL-Datenbanken haben ihre eigenen Abfragesprachen, von denen viele lose auf SQL basieren. Die Cassandra Query Language (CQL) wird zur Abfrage von Cassandra-Datenbanken verwendet. MongoDB verfügt über Treiber, die es ermöglichen, mit verschiedenen Sprachen wie Java oder C# zu interagieren, und hat seine eigene interne Shell-Sprache, MongoDB Query Language (MQL), die auf JavaScript basiert.
NoSQL-Datenspeichermodelle
Der Begriff Datenspeicher bezieht sich auf das Speichermodell, das von einer nicht-relationalen Datenbank verwendet wird, zum Beispiel können Daten als Dokumente, Bilder oder Graphen gespeichert werden. NoSQL-Datenbanken basieren auf vier wichtigen Datenspeichermodellen: Key-Value-Store, Dokumentenspeicher, spaltenorientierter Speicher und Graphenspeicher. Weniger gebräuchliche, eher spezialisierte Modelle sind Zeitreihen-, Objekt- und externe Indexspeicher.
Schlüssel-Wert-Speicher
Ein Schlüssel-Wert-Paar oder Name-Wert-Paar ist eine Dateneinheit, die durch einen Namen und den Wert des Inhalts identifiziert wird, z. B. key=country und value=bolivia. Mithilfe von Schlüssel-Wert-Paaren können Entwickler offene, hoch skalierbare Datenstrukturen erstellen, die nicht durch Größe oder Typ eingeschränkt sind und sich leicht partitionieren lassen, um schnellere Abfragen zu ermöglichen. Datenbanken, die auf dem Key-Value-Modell basieren, gelten als die einfachste Version von NoSQL-Datenbanken. Beispiele für Key-Value-Datenbanken sind Redis und Amazon DynamoDB.
Eine NoSQL-Datenbank wird oft allgemein als Key-Value-Datenbank bezeichnet. Einige NoSQL-Datenbanken können als hybride Key-Value-Datenbanken betrachtet werden. Cassandra von Facebook zum Beispiel ist eine Schlüssel-Wert-Datenbank und eine spaltenorientierte Datenbank. Die Oracle NoSQL-Datenbank ist eine verteilte Key-Value-Datenbank.
Dokumentenspeicher
Eine Datenbank, die auf dem Dokumentenspeichermodell basiert, ist für die effiziente Speicherung von Dokumenten in einer einzigen Instanz konzipiert. Medienunternehmen wie Zeitungshäuser und Wissensdatenbank-Systeme verwenden Dokumentenspeicher-Datenbanken, um Artikel, Zusammenfassungen, Blogs und Beiträge zu speichern. Eine Dokumentenspeicher-Datenbank speichert Dokumente in ihrer Gesamtheit, sodass jedes Dokument leicht zugänglich ist. Würden die Dokumente in einer relationalen Datenbank gespeichert, müsste ein typischer Artikel in zusammengesetzte, logische Teile aufgeteilt werden – z. B. Informationen über den Autor, den Inhalt und Kommentare von Lesern – und dann mit Querverweisen auf einen Schlüssel wie den Autor versehen werden. Beispiele für Dokumentenspeicherdatenbanken sind MongoDB und Elasticsearch.
Säulenorientierte Speicherung
Relationale Datenbanken sind zeilenorientiert, während nicht-relationale Datenbanken spaltenorientiert sind. Datenbanken, die auf dem spaltenorientierten Modell basieren, speichern die Spalten, die in den Zeilen einer relationalen Datenbank zu finden sind, separat mit individuellen IDs. Eine spaltenorientierte Datenbank ist in der Lage, bei der Suche nach Daten nur die Spalten zu durchsuchen, an denen sie interessiert ist, während zeilenorientierte Datenbanken alle Spalten in einem Datensatz durchsuchen müssen, wenn sie Daten nach einer bestimmten Spalte filtern. Ein Beispiel für eine spaltenorientierte Datenbank ist Cassandra von Facebook.
Graph-Speicherung
Graph-Speicher beziehen sich auf Sammlungen von Beziehungen. Datenbanken, die auf dem Graph-Store-Modell basieren, werden von Social-Media-Plattformen ausgiebig genutzt, da sie darauf ausgelegt sind, Knoten mit mehreren Kanten zu verbinden und so Cluster verwandter Informationen zu bilden. In einer Graphdatenbank ist ein Knoten eine primäre Dateneinheit, zum Beispiel eine Person oder ein Unternehmen. Kanten beschreiben die Beziehungen eines Knotens zu anderen Knoten und Kanten, z. B. die Kunden, Filialen, Mitarbeiter, Produkte usw. eines Unternehmens. Kanten in einer Graphdatenbank sind selbst Knoten, die mit verschiedenen Kanten verbunden sind. Ein Beispiel für eine Graphdatenbank ist Neo4j.
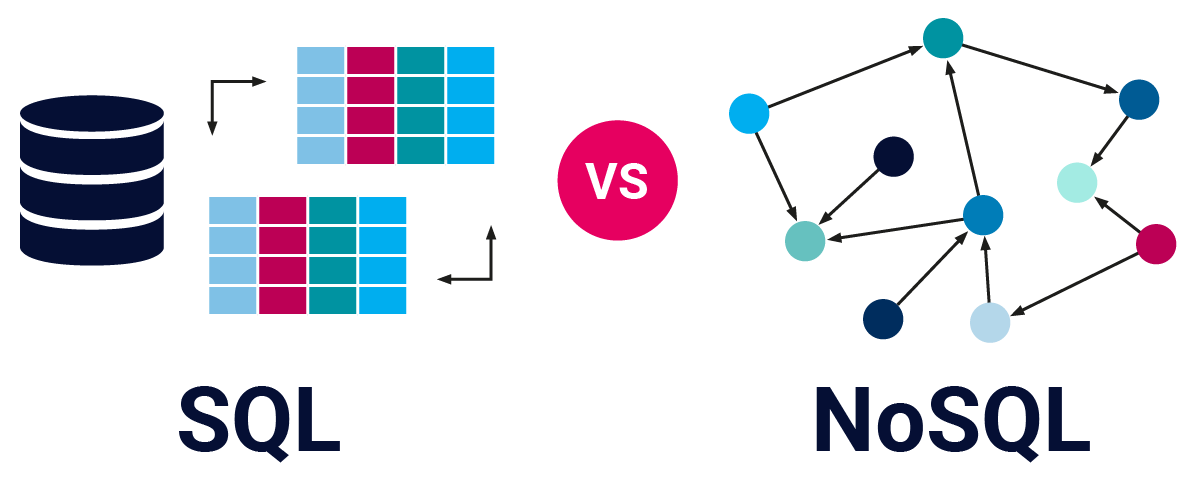
NoSQL-Datenbanken
Zentralisierte Datenbank
Eine zentralisierte Datenbank wird an einem einzigen Ort betrieben, z. B. eine Datenbank auf dem Universitätsgelände. Eine zentralisierte Datenbank ist nicht dasselbe wie ein zentralisierter Datenbankmanager. Moderne Unternehmen verwenden zentralisierte Datenbankmanagementsysteme, die aus mehreren Datenbanken bestehen, um unterschiedliche Daten zu speichern und zu verwalten. Eine zentralisierte Datenbankverwaltung hilft Unternehmen, die Sicherheit, Integrität und Konsistenz ihrer Daten sowie die betriebliche Effizienz zu gewährleisten.
Cloud-Datenbank
In einer Cloud-Umgebung ist eine Cloud-Datenbank ein Datenbankdienst. Eine Organisation kann bei einem Cloud-Anbieter virtuellen Speicherplatz erwerben, auf dem sie ihre Datenbank bereitstellen kann. Alternativ kann eine Organisation ein Abonnement für ein Datenbank-as-a-Service-Angebot (DBaaS) erwerben, das Datenbankmanagement, Wartung und Betriebsdienste umfassen kann. DBaaS ist das Datenbankäquivalent zu Software as a Service (SaaS). Cloud-Datenbanken werden in der Regel von Unternehmen genutzt, die ein hohes Verkehrsaufkommen haben und deren Kunden geografisch verteilt sind. Beispiele für Cloud-Datenbanken sind MySQL, IBM Db2 und Microsoft SQL Server.
Spaltenorientierte Datenbank
Eine spaltenorientierte Datenbank ist ein DBMS, das Daten in Spalten statt in Zeilen speichert. Spaltenbasierte Datenbanken werden hauptsächlich in analytischen Anwendungen verwendet, da auf die Daten sehr schnell zugegriffen werden kann, sowie in Data Warehouses. In zeilenbasierten Datenbanken werden die Zeilen in zusammenhängenden Blöcken auf einer Festplatte gespeichert. Bei spaltenbasierten Datenbanken werden die Spalten in zusammenhängenden Blöcken auf einer Festplatte gespeichert. Wenn ein Unternehmen nur Daten für eine bestimmte Spalte oder Gruppe von Spalten abrufen und analysieren muss und alle anderen Daten in einem Datensatz ignorieren möchte, sind spaltenorientierte Datenbanken effizienter. Beispiele für spaltenorientierte DBMS sind ClickHouse, MariaDB und Apache Cassandra.
Verteilte Datenbank
In einer verteilten Datenbank werden die Daten an mehreren physischen Standorten oder auf mehreren Computern am selben physischen Standort gespeichert. Für die Benutzer erscheint die Datenbank als eine einzige Datenbank.
Flat Files
Flat Files sind Textdateien, in denen die Dateneinträge in der Regel durch Begrenzungszeichen wie Kommas getrennt sind. Flat Files sind nicht-relationale Datenspeicherdateien, aber die Daten können mit relationalen Datenbankdaten unter Verwendung von Datenbankverwaltungsanwendungen wie Microsoft Access integriert werden. Ein gängiges Beispiel für eine Flat File ist eine CSV-Datei (comma-separated values).
Hierarchische Datenbank
In einer hierarchischen Datenbank werden die Daten in einer Baumstruktur gespeichert. Die Daten werden aus einer hierarchischen Datenbank abgerufen, indem die Baumstruktur mithilfe von Zeigern von oben nach unten durchlaufen wird.
Eine hierarchische Datenbank verwendet ein Eins-zu-N-Beziehungsmodell, bei dem ein übergeordneter Knoten mehrere untergeordnete Knoten haben kann. Ein Beispiel für ein hierarchisches Datenspeichermodell ist die Darstellung von Ordnern und Dateien in Dateimanagern wie dem Windows Explorer.
In-Memory-Datenbank
Eine In-Memory-Datenbank (IMDB) speichert Daten auf flüchtigen Speichermedien oder im Kurzzeitspeicher (RAM) eines Computers, was einen schnelleren Datenzugriff ermöglicht. Traditionell gehen bei einem Stromausfall auch die Daten verloren. In modernen Systemen ermöglicht die Technologie des nichtflüchtigen Arbeitsspeichers die Aufrechterhaltung von In-Memory-Daten auch bei einem Stromausfall. Dies wird u. a. durch ein automatisches Failover erreicht.
In den 1970er-Jahren, als relationale Datenbanken entwickelt wurden, war Speicher teuer. Heute können Anwendungen mit IMDBs effizient ausgeführt werden, ohne dass im Falle eines Stromausfalls Informationen verloren gehen. Anwendungen, die eine hohe Leistung und geringe Latenzzeiten erfordern – wie Online-Spiele, Geodatenverarbeitung, maschinelles Lernen, Analyse medizinischer Geräte – können nichtflüchtige IMDBs in Verbindung mit plattenbasierten Datenbanken verwenden.
Viele Datenbanken bieten In-Memory-Optionen, wie Memcached und Redis. Die Apache Ignite-Plattform erstellt eine In-Memory-Schicht über jeder bestehenden Datenbank. Beispiele für „reine“ IMDBs sind SQLite, Exasol, SAP HANA und IBM solidDB.
JSON-Datenbank
Wie XML wird auch die JavaScript Object Notation (JSON) als rudimentäre Datenbank beschrieben. JSON ist ein offenes Datenaustauschformat, das zur Beschreibung von Daten verwendet wird. Es ist auch eine Art von Dokumentendatenbank, die zum Speichern von Katalogen auf E-Commerce-Websites und zur Bereitstellung von Live-Updates auf Websites verwendet werden kann.
TaffyDB ist ein Flat-File-Datenbanksystem, das JSON zum Speichern von Daten verwendet.
Netzwerk-Datenbank
In einer Netzwerkdatenbank können Datensätze aus mehreren Tabellen mit einem einzigen Datensatz aus einer anderen Tabelle verknüpft werden. Im Gegensatz zu einer traditionellen relationalen Datenbank, die auf Schlüsseln basiert, ist eine Netzwerkdatenbank zeigerbasiert.
Ein Netzwerk-Datenbankmodell wird als eine erweiterte Version eines hierarchischen Datenmodells betrachtet, da es eine Graphenstruktur anstelle einer Baumstruktur verwendet. In Netzwerkdatenbanken werden die übergeordneten Knoten als Besetzer (occupier) und die untergeordneten Knoten als Mitglieder (member) bezeichnet. In einer Netzwerkdatenbank kann ein Mitgliedsknoten mehr als einen Besetzerknoten haben. Die Besetzer- und Mitgliedsknoten bilden eine Menge. Die Entitäten in diesem Modell stehen in einer Many-to-many-Beziehung.
Objektorientierte Datenbank
Eine objektorientierte Datenbank speichert Daten in Form von Objekten, wie sie in der objektorientierten Programmierung verwendet werden. In objektorientierten Systemen können Objekte persistiert werden. Bei persistierten Daten handelt es sich um Daten, die über einen längeren Zeitraum aufbewahrt werden, als sie ursprünglich erstellt wurden, und die auf nichtflüchtigen Speichermedien gespeichert werden. Eine objektorientierte Datenbank verwendet ein Many-to-many-Beziehungsmodell. Der Zugriff auf die Daten erfolgt mithilfe von Zeigern. Beispiele für objektorientierte Datenbanken sind Magma und die mobile Datenbank von Realm.
Objektrelationale Datenbank
Objektrelationale Datenbanken sind hybride Datenbanken, die Merkmale relationaler Datenbanken und objektorientierter Datenbanken kombinieren. Objektrelationale Datenbanken zeichnen sich dadurch aus, dass sie Aggregatstypen unterstützen, z. B. Listen und Mengen. Ein Beispiel hierfür ist eine Spalte mit der Bezeichnung „Adresse“ in einer relationalen Datenbank, die eine Liste verwandter Informationen wie Wohn- und Ferienhäuser usw. enthalten kann. Beispiele für objektrelationale Datenbankmanagementsysteme (ORDBMS) sind PostgreSQL und Oracle.
Online-Transaktionsverarbeitungs-Datenbank (OLTP)
Ein OLTP-Datenbanksystem befasst sich mit mehreren Transaktionen, die gleichzeitig von mehreren Benutzern durchgeführt werden, z. B. in E-Commerce-Anwendungen. Eine OLTP-Datenbank verwaltet in der Regel kleine Datenmengen gleichzeitig, z. B. bei Online-Banking-Transaktionen, muss aber eine große Anzahl von Benutzern unterstützen. Zu den Datenbanken, die häufig für OLTP verwendet werden, gehören MySQL, InterSystems Caché und VoltDB, eine NewSQL-Datenbank, die mit Atomicity, Consistency, Isolation, Durability (ACID) konform ist.
Persönliche Datenbank
Jedes physische Medium, auf dem Daten gespeichert werden können, ist eine Datenbank, auch eine Festplatte in einem Computer. Bei den in der IT verwendeten und diskutierten Datenbanken handelt es sich jedoch in der Regel um komplexe Datenspeichermodelle.
Ein Beispiel für die Speicherung persönlicher Daten sind die Daten, die auf persönlichen Geräten wie Computern, Handys, Tablets und externen Festplatten gespeichert sind. Auf diese Daten wird von Anwendungen wie Microsoft Office, Systemanwendungen, die Konfigurations- und Benutzerdaten speichern, und funktionalen Anwendungen zugegriffen und diese verwaltet.
Auch persönliche Geräte nutzen IMDBs wie RAM, um die Geräteleistung zu verbessern.
XML-Datenbank
Wie JSON wird auch eine Extensible Markup Language (XML)-Datenbank als rudimentäre Datenbank bezeichnet. XML ist eine Art von Dokumentendatenbank in dem Sinne, dass XML-Dateien mit der Erweiterung .xml gespeichert werden, sie können Daten speichern, die dem XML-Format entsprechen, und sie können mit einem Sprachabfragetool wie XQuery abgefragt werden.
Hybride Datenbanksysteme
Die einzigartigen Merkmale von relationalen und nicht-relationalen Datenbanken in modernen Anwendungen haben sich in einigen Datenbankimplementierungen zu Datenbanksystemen mit mehreren Modellen zusammengeschlossen. OrientDB ist zum Beispiel eine NoSQL-Graph-Datenbank, deren Knoten Dokumente sind.
Eine Datenbank, die relationale und nicht-relationale Datenbankfunktionen integriert, ist eine weitere Art von hybrider Datenbank, zum Beispiel NewSQL.
Eine dritte Art von Hybriddatenbank ist eine Kombination aus einer IMDB und einer On-Disk-Datenbank. Bei dieser Art können die Daten im Hauptspeicher, auf einer Festplatte oder auf beiden Speichermedien gespeichert werden. Ein Beispiel für diese Art von hybrider Datenbank ist Altibase.
Ihr Datenbankmonitor PRTG auf einen Blick
Datenbank-Überwachungstools - Dashboard-Übersicht
Einheitliche Datenbanküberwachung
Microsoft SQL-Sensor
DBMS-Funktionen sind Softwarekomponenten, die Gruppen von zusammenhängenden Aufgaben verwalten. Zu den DBMS-Funktionen gehören Wörterbuch-, Speicher-, Transformations-, Präsentations-, Sicherheits-, Zugriffskontroll-, Sicherungs- und Wiederherstellungsmodule, Datenintegritäts-, Zugriffs-, Schnittstellen-, Gleichzeitigkeits- und Transaktionsmanagementmodule.
Ein DBMS speichert zum Beispiel Datenelemente und Metadaten in einem Datenwörterbuch. Ein DBMS ermöglicht nicht nur die Speicherung von Daten, sondern auch von datenbezogenen Elementen wie Validierungsregeln, Formularen und Berichtsdefinitionen sowie Schemata, die die Datenbankstruktur beschreiben. Die DBMS-Funktionen sind miteinander verknüpft, z. B. verwaltet ein Zugriffskontrollmodul den Datenzugriff; die Mehrfachzugriffskontrolle ermöglicht mehreren Benutzern den Zugriff auf die Datenbank, ohne die Datenintegrität zu beeinträchtigen.
Daten werden in RDBMS und DBMS unterschiedlich gespeichert, abgerufen und verwaltet. In einem RDBMS werden die Daten in Tabellenzeilen gespeichert und der Zugriff erfolgt über eine eindeutige Zeilenkennung, den sogenannten Primärschlüssel. Ein RDBMS unterstützt Normalisierung und verteilte Datenbanken und unterstützt mehrere Benutzer. In einem DBMS werden die Daten entweder in einer Navigations- oder in einer hierarchischen Form gespeichert. Ein DBMS unterstützt weder Normalisierung noch verteilte Datenbanken und unterstützt nur einzelne Benutzer.
Es gibt keine formale Spezifikation dafür, was eine Datenbank ist, aber es gibt mehrere De-facto-Standards, die Leitlinien für die Gestaltung von Datenbanken bieten, die den internationalen Datenvorschriften entsprechen.
Konsistenz
Eines der Hauptmerkmale von Datenbanken, nämlich die Konsistenz, basiert auf einem von zwei theoretischen Modellen: dem ACID-Modell (atomicity, consistency, isolation und durability) und dem BASE-Modell (basically available, soft state, eventual consistency).
Eine Datenbank, die das ACID-Modell verwendet, garantiert, dass Daten sicher und konsistent gespeichert werden, d. h. wenn ein Prozess Daten speichert und signalisiert, dass die Daten gespeichert wurden, besteht keine Möglichkeit, dass Daten auf dem Weg dorthin verloren gegangen sind. Relationale Datenbanken verwenden immer das ACID-Modell, und einige NoSQL-Graph-Datenbanken sind so konzipiert, dass sie dem ACID-Modell entsprechen.
Bei einer Datenbank, die das BASE-Modell verwendet, liegt der Schwerpunkt auf der hohen Verfügbarkeit der Daten zu Skalierungszwecken. Nicht-relationale Datenbanken sind in der Regel so konzipiert, dass sie dem BASE-Modell entsprechen.
Normalisierung
Normalisierung ist der Prozess der Organisation von Daten in einer Datenbank. Die Normalisierung umfasst die Erstellung von Tabellen und die Zuordnung von Beziehungen zwischen den Tabellen nach bestimmten Regeln, die darauf abzielen, die Daten zu schützen, Redundanz (Duplizierung) zu beseitigen und sicherzustellen, dass es keine Anomalien gibt. Ein Beispiel für eine typische Anomalie, die durch die Normalisierung verhindert wird, ist die Erstellung von Informationen über einen Verkauf, ohne zuvor Informationen über das zu verkaufende Produkt zu erstellen.
Persistenz
Die Datenpersistenz gewährleistet, dass gespeicherte Informationen auch dann wiederhergestellt werden können, wenn das Speichermedium oder das System, das die Daten verwendet, nicht mehr angeschlossen ist. Ein Beispiel für Persistenz ist die Möglichkeit für einen Benutzer, seine letzten Browserfenster wiederherzustellen, nachdem sein Computer abgestürzt ist.
Skalierung
Unter Skalierbarkeit versteht man die Fähigkeit einer Datenbank, ein Wachstum zu bewältigen, z. B. ein größeres Datenvolumen und mehr Nutzer. So müssen beispielsweise soziale Netzwerke sehr skalierbar sein, um die ständige Vernetzung von Menschen mit neuen Personen, das Posten von Nachrichten und das Hochladen von Daten zu verwalten.
Integrität der Daten
Datenintegrität bezieht sich auf die Genauigkeit, Vollständigkeit, Konsistenz, Sicherheit und Unversehrtheit von Daten. Datenintegrität ist für die Einhaltung von Vorschriften wie der Allgemeinen Datenschutzverordnung (GDPR) unerlässlich.
Kardinalität
Die Kardinalität bezieht sich auf die Beziehung zwischen den Daten in einer Datenbanktabelle und einer anderen Tabelle und ist mit dem Konzept der Datenintegrität verbunden. Ein Beispiel für Kardinalität ist die Angabe, ob die Beziehung zwischen Datenwerten viele zu vielen, eins zu eins oder viele zu eins ist, z. B. darf eine Person nur eine Sozialversicherungsnummer haben. Die Kardinalität ist wichtig, weil sie sich darauf auswirkt, wie effizient Abfragen in Datenbanken zum Abrufen von Informationen durchgeführt werden.
Relationale Datenbanken
Relationale Datenbanken bieten eine bessere Konsistenz und Zuverlässigkeit als nicht-relationale Datenbanken und vermindern die Datenredundanz. Relationale Datenbanken bieten einen einfachen Zugriff auf Daten durch ein einfaches, bewährtes Abfragemodell, hohe Sicherheit, Datenintegrität und Normalisierung.
Relationale Datenbanken unterstützen ACID-Eigenschaften und gewährleisten zuverlässige Datenbanktransaktionen. Sie unterstützen komplexe Abfragen und bieten eine unbegrenzte Indexierung.
Nicht-relationale Datenbanken
Nicht-relationale Datenbanken bieten eine bessere Leistung und verarbeiten große Datenmengen schneller als relationale Datenbanken. Sie bieten hohe Verfügbarkeit und benötigen kein Schema.
Nicht-relationale Datenbanken sind horizontal skalierbar, d. h. sie lassen sich durch Hinzufügen weiterer Knoten erweitern. Die Skalierbarkeit in nicht-relationalen Datenbanken ist kostengünstiger als in relationalen Datenbanken.
Nicht-relationale Datenbanken können unterschiedliche Datentypen wie Nachrichten-Feeds, Audio- und Videostreams und Daten aus mobilen Anwendungen speichern und verwalten, ohne die Architektur zu verändern.
Relationale Datenbanken
Im Vergleich zu anderen Datenbanktypen sind relationale Datenbanken aufgrund der Art und Weise, wie sie Daten physisch speichern, langsam und verbrauchen mehr Speicherplatz. Der Prozess der Normalisierung kann viele Verknüpfungen (Mapping-Tabellen) erfordern, was die Geschwindigkeit des Datenabrufs ebenfalls verlangsamt.
Relationale Datenbanken arbeiten mit vertikaler Skalierbarkeit, d. h., sie erweitern sich, indem sie die Kapazität der vorhandenen Knoten erhöhen. Die Skalierbarkeit in relationalen Datenbanken ist kostspieliger als in nicht-relationalen Datenbanken.
Relationale Datenbanken können komplex werden, wenn es viele Tabellen gibt, und es kann immer komplizierter werden, mit anderen, ähnlich komplexen Systemen zu interagieren.
Relationale Datenbanken sind in der Wartung teurer und unterstützen keine unstrukturierten Daten. Außerdem sind die Feldlängen begrenzt.
Nicht-relationale Datenbanken
Nicht-relationale Datenbanken verwenden keine standardisierte Abfragesprache, und die von den Anbietern entwickelten benutzerdefinierten Sprachen sind oft nicht so leistungsfähig wie SQL. Für sie stehen nicht so viele Werkzeuge zur Verfügung wie für relationale Datenbanken.
Nicht-relationale Datenbanken sind nicht so sicher wie relationale Datenbanken. Sie verfügen weder über eingebaute Datenintegrität noch unterstützen sie ACID, sondern verlassen sich auf „eventuelle Konsistenz“.
NoSQL-Datenbanken weisen ein geringeres Maß an Normalisierung auf als SQL-Datenbanken und können daher Datenredundanzen enthalten.
Es gibt wenig Einheitlichkeit zwischen nicht-relationalen Datenbanken oder standardisierte Schnittstellen für die Kommunikation zwischen ihnen.
Zwei der Hauptgründe für die Verwendung einer Datenbank sind der schnelle und effiziente Zugriff auf Daten und die Gewährleistung der Datenpersistenz. Moderne Anwendungen – von Social-Network-Seiten über Wettervorhersagen bis hin zu künstlicher Intelligenz – erfordern enorme Datenmengen, die in Echtzeit verarbeitet werden müssen. Während statistisch gesehen relationale Datenbanken immer noch am häufigsten verwendet werden, integrieren moderne Datenbanksysteme oft eine Vielzahl von Open-Source- oder proprietären Datenbanken, DBMS, physischen und virtuellen Speichern und Datenbank-Frameworks.
NewSQL ist ein relationales Datenbankmanagementsystem, das die skalierbaren Eigenschaften einer NoSQL-Datenbank aufweist. NewSQL-Datenbanken unterstützen ACID, OLTP, vertikale und horizontale Skalierung, komplexe Abfragen, mehrere Speichertypen und verteilte Datenbanksysteme.
Ein Beispiel für ein modernes, kombiniertes Datenbanksystem ist Spanner von Google. Spanner ist ein verteilter SQL-Datenbankverwaltungs- und -speicherdienst, wird aber in der Regel als Cloud-gehostete NewSQL-Datenbank bezeichnet. Relationale Datenbanken unterstützen zwar SQL und sind konsistenter als NoSQL-Datenbanken, lassen sich aber nicht so gut skalieren wie NoSQL-Datenbanken. Spanner ist eine relationale Datenbank, bietet aber die Art von Funktionalität, für die NoSQL-Datenbanken entwickelt wurden, wie globale Skalierbarkeit, optimierte Leistung durch automatisches Sharding, hohe Verfügbarkeit und minimale Latenz. Sharding ist der Prozess der Verteilung von Daten aus einer überlasteten Datenbank in mehrere kleinere Datenbanken, um die Last zu verteilen.
Weitere Beispiele für NewSQL-Datenbankprodukte und -dienstleistungen sind MemSQL, Infobright, ScaleBase und TransLattice.
Die Datenbanküberwachung gewährleistet eine optimale Datenleistung und Ressourcennutzung. Die SQL-Leistung wird beispielsweise daran gemessen, wie schnell und effizient SQL-Abfragen ausgeführt werden, und die Speicherplanung hilft, die tatsächlich benötigte Kapazität abzuschätzen, bevor die Speichergrenzen erreicht werden.
Die proaktive Überwachung von Datenbanken identifiziert potenzielle Probleme, bevor sie sich zu größeren Sicherheitsverletzungen ausweiten, und ist zwingend erforderlich, um Datenschutzgesetze wie die GDPR einzuhalten.
Die Leistung einer Datenbank hat einen direkten Einfluss auf die Betriebszeit, die Ladegeschwindigkeit von Webseiten, die geografische Leistung, die effiziente Hardwarenutzung und die Kundenerfahrung.
- https://www.sciencedirect.com/topics/computer-science/database-languages
- https://beginnersbook.com/2015/04/dbms-languages/
- https://www.quora.com/What-query-language-does-MongoDB-use
- https://dzone.com/articles/nosql-database-types-1
- https://www.mongodb.com/databases/what-is-an-object-oriented-database
- https://aws.amazon.com/nosql/columnar/
- https://www.researchgate.net/publication/269402357_IBM_solidDB_In-Memory_Database_Optimized_for_Extreme_Speed_and_Availability
- http://www.cburch.com/cs/340/reading/ordbms/index.html#:~:text=
Examples%20of%20ORDBMSs%20include%20
PostgreSQL,sets%2C%20lists%2C%20and%20structs - https://www.techopedia.com/definition/30558/xml-database
- https://www.tvisha.com/blog/what-is-the-difference-between-dbms-and-rdbms
- https://docs.microsoft.com/en-us/office/troubleshoot/access/database-normalization-description#:~:text=Normalization%20is%20the%20process%20of,
eliminating%20redundancy%20and%20inconsistent%20dependency. - https://www.xenonstack.com/blog/sql-vs-nosql-vs-newsql
- https://www.networkworld.com/article/3197692/how-google-s-cloud-is-ushering-in-a-new-era-of-sql-databases.html
Interne Quellen
- https://blog.paessler.com/10-website-performance-indicators-you-should-monitor
- https://blog.paessler.com/why-monitoring-a-database-requires-an-it-professional
- https://blog.paessler.com/monitoring-sql-server-performance-with-prtg
- https://blog.paessler.com/storage-capacity-planning-with-prtg
- https://blog.paessler.com/track-your-gdpr-compliance-with-prtg
- https://blog.paessler.com/ransomware-on-the-rise-network-buzzwords-watch-and-gdpr-readiness